


In December, I was fortunate enough to be invited to present a talk at the MLOps World Vancouver virtual event. I was intrigued, and after bouncing around a couple of ideas with the organizers to feel out what they really needed, I was drawn towards talking about some of the more strategic aspects of creating business value using the set of up-and-coming technologies labeled and buzzworded with the moniker of “MLOps”.
These new technologies, it so happens, are the same ones that I’m doing my best to figure out how to teach to the next generation of data scientists, machine learning engineers, and software engineers.
🎯 Starting With the End in Mind
First, I asked myself, where is this talk headed? What is my actual super-quick advice for folks out in the industry trying to create real business value? I came up with three bullets.
MLOps business value is business-model dependent
It is hard to create value; start close to your bottom line
Running lean and setting up automatic data capture is underrated
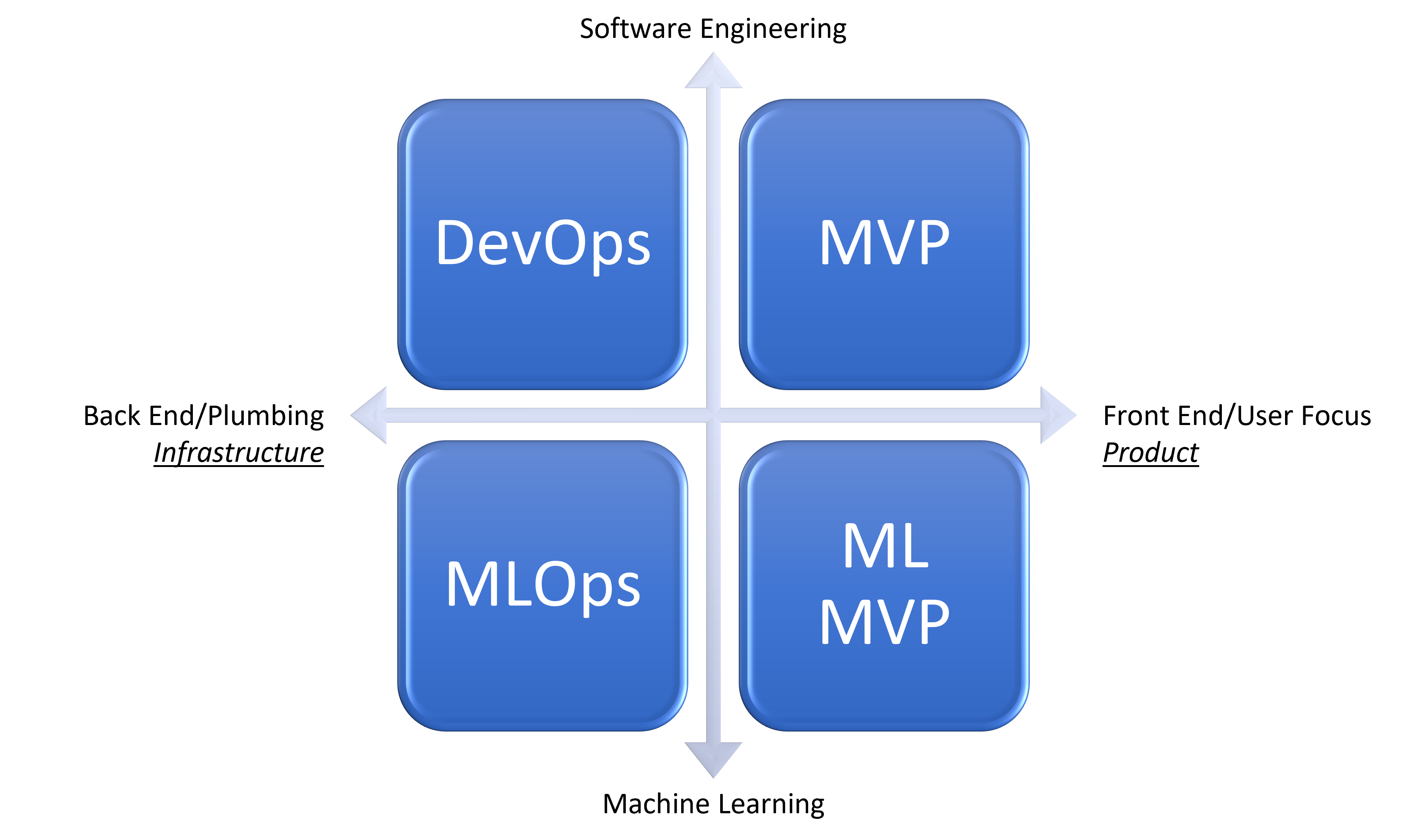
The MLOps Business Value Framework
After coming up with my top-level assertions I then conceptualized the next layer of detail in my framework. I organized this layer into four “problem” dimensions along which a machine learning team lead might have decision-making responsibilities.
The set of four included product, infrastructure, process, and people problems. Another way I conceptualized this was the why, what, how, and who problems of MLOps. The last set of four that I came up with gave me some feelings of synchronicity: I felt like I really had something worth sharing. The machine learning, operations, tools, and organization problems appeared to map directly to the other two.


🤔 Product Problems
As a full-time product person as well as a machine learning practitioner and instructor, I found that I had a LOT to say about product problems, especially for data-centric AI products. Much more than would fit in my short talk.
However, I thought that I could connect with the MLOps World audience by introducing the idea that sometimes massive business value lies just beyond the grasp of the obvious, and just beyond the data that we have today. I wanted to introduce the idea of what such hidden gems actually look like.
So what do they look like?
Well, they look like digital products that drink from the Holy Grail of MLOps business value, producing what is called a Data Network Effect.
What is this alchemy called a data network effect?
When you combine automatic data capture, with automatic additional value creation, where the minimum threshold of users has been achieved, there is no asymptotic limit of the value that can be achieved, the value of the data is central to the overall value of the product, and users actually perceive that value, you’ve got yourself a great chance to achieve data network effects.
This is, of course, both extremely rare and incredibly worthwhile. A worthy aim, indeed.
When you think of data network effects, think of digital products or apps like Waze, where the updates only work if the data is based on real-time information. Algorithms are continuously being re-trained, providing the best possible experience, which pushes more users to the product, resulting in more and better data, providing more accurate predictions (of where cops are, etc.), which creates more value for users, and on and on. A virtuous cycle, indeed.
So that was the hook.
And it was necessary because the reality is much less sexy. Business value generally is not created through data network effects, crypto, or some other web3 technology like decentralized autonomous organizations. The reality is that the business value is in the mundane.
The way that I like to put it is that:
The problem is still the problem
That is, the problem is the problem that your product is trying to solve in the first place. Does it even need to leverage data and use machine learning? This may be the hardest question of all to answer, because it forces you to properly contextualize the role of AI and ML in your organization, on your team, and for your own specific role. In short, it forces you to look at the value that you actually deliver today, in terms of bottom-line revenue (PS … or in terms of your north star metric; it’s not always directly about revenue).
Since data science is fundamentally an R&D function, this can be an eye-opening and humbling thing to do. It is hard to command salaries as researchers because it is hard to create massive value through searching and re-searching.
But we can learn from the OGs of AI-first business value. Let’s take a look at the first step in creating value through machine learning if you work for the best of the best:
Apple asks: What is the role of ML in your app?
Google starts with: Where’s the intersection of what AI is capable of and what the people using your service require?
Microsoft inquires: What should a person know when they first use your system?
Spotify asks you to: Identify where the people using your service are facing friction?
Facebook keeps it real with: What problem are you trying to solve?
Elon Musk also puts it well. His advice is to start by “[making] your requirements less dumb.”
In short, “knowing not to do something is just as valuable as knowing what to do,” says an old buddy of mine who is now a product manager and leader at C3 AI in San Francisco.
If we get right down to it, this function of “figuring out what not to do” is the primary role of R&D scientists and engineers in general, from atoms to bits, everywhere. And it’s also the primary role of data scientists and machine learning practitioners. Considering the amount of data that is generated every day, and our industry’s continued focus on data-centric AI over big data, it appears that this skill of separating the wheat from the chaff and optimizing complex systems via negativa will only become more valuable in the 21st century.
What we’re really talking about here is the skill of identifying worthy ML pilot projects, and of moving beyond being surprised when a system that achieves 99% accuracy on a test set doesn’t perform well on a business application. What we’re talking about is becoming good at doing things that don’t scale.
Of course, though these ideas are not new, they do depend on connecting lower-level metrics (like data and model accuracy or cost functions) to top-level Key Performance Indicators, or KPIs. To keep it simple, let’s say that you should connect directly, intuitively, whatever model that you build to at least one top-level KPI.

The Institute for Ethical AI & Machine Learning calls this idea Practical Accuracy, and Principle 6 reads
“I commit to develop processes to ensure my accuracy and cost metric functions are aligned to domain-specific applications.”
In the end, then, what’s the product problem when it comes to creating real business value with MLOps?
The answer is that once you figure out the problem that your product solves, you then have to ask yourself how data, machine learning, and an AI-first approach will help you solve that problem better, in a clear and obvious way, and in a way that puts your ML-first approach at the top of your product prioritization list.
So, in short, while this is not new for product managers, it is new for most MLOps practitioners.
The problem is still the problem.
🏗️ Infrastructure Problems
When we think about moving from the product-side to the infrastructure-side of business value, things get even harrier. While the terminologies for an ML MVP don’t yet exist beyond “pilot projects,” the idea of when to actually implement an MLOps infrastructure solution is a decision that’s been made orders of magnitude fewer times in the business world today than to greenlight some AI pilot projects.
The parallel that we must draw is to agile teams in high-growth startups today. These teams are often faced with the decision to actively stop work on product-side features and user experience improvements and focus instead on bug fixes, performance improvements, or in the most extreme cases, complete overhauls of the pipelines and plumbing used to deliver a product or service.
The thing to remember is that this type of work is basically never aimed at short-term business value, especially in any sort of direct way.
Another more straightforward way of stating this same idea is that
An ML system IS a software system
It’s just more dynamic than a classical software system due to the complexity added when “code” is made of both data and a machine learning model.
So things can change that didn’t use to change.
To drive the point home another way, AI adds complexity.
As we go from DevOps to MLOps, we add another layer of abstraction. Considered from a first-principles perspective Continuous Training must necessarily sit atop Continuous Integration, Continuous Delivery, and Continous Deployment practices.
Today, companies whose core product is not an AI-first or ML-first product (which is the vast majority of companies in existence) are often just trying to take one pilot project into production, and see how it goes. See if it moves that top-level KPI when an A/B test is actually completed.
These companies are not trying to set up massive infrastructure projects that allow for continuous training, retraining, and piloting of tons of new projects.
As I like to say, setting out to create some grand infrastructure without a lean process for piloting ML projects and continuously training and retraining existing ones is kind of like having a V12 Lamborghini that you only ever drive in downtown San Francisco. Sure, you could, and always upgrade to the latest model next year, but why would you want to? The answer is something like because you’ve never taken a hard look at the problem that the Lamborghini is actually solving for you, and how you might solve that problem in a way that truly maximizes business value.
🔁 Process Problems
Keeping in mind that all products do not need and do not actually use ML, you should be working to build your stream of pilot projects.
If you’re like most companies, you’ll probably start with one model and an external consultant. If you’re lucky, you’ll do this enough times to get one model into production. After that, eventually, you’ll realize that you should retrain that one model.
Now you’re on the path. You’ve been through one iteration, and have done some retraining and some monitoring in operation.
Now keep that model going.
And start piloting another model.
If you’re really lucky, this next model might eventually make it to production as well (at least the 10th or so iteration of it, if you formulate the problem that it’s trying to solve well enough).
At this point, maybe you make your first full-time hire, and you stop using external consultants. Now it’s really time to build process and get buy-in up and down the chain of command and to establish the way that pilot projects are created, tested, and put into production.
As Spotify says, go manual before you go magical.
Once you can run these processes manually, then you might consider automating.
Once you’ve exhausted the limits of hack-job automation and low-code solutions, once you have a team and are creating new pilots, and training and retraining operational models in production environments, and doing all of these things all of the time, this is probably where you might start looking at additional operational tools (see Infrastructure Problems).
But first, remember all that process you just set up? Yea, there are no real industry standards in terms of the people who are going to help you do that, what their titles are, and how they are to work together with one another.
🧑🤝🧑 People Problems
The final piece to our MLOps problem and solution puzzle is to take a good hard look at the people who are helping your organization to identify and grok problems, collect and munge data, build and curate models, select tools for these jobs, and ultimately, to set up processes where none existed before.
Ask yourself, who is responsible for creating business value with AI and ML in my organization, exactly? And how should these folks be organized and work together?
As Peter Drucker says in The Effective Executive:
“One should only have on the team the knowledge and skills that are needed day in and day out for the bulk of the work.”
When it comes to data science and agile software development, engineering, and operations, some experts recommend separation, and others recommend integration. The real expert, however, works for your particular organization and knows that it depends on many factors, not least of which is the cultural bedrock on which all of your products have ever been constructed.
It may sound cliche, but when it comes to people problems, there are no easy answers.
If you’re a small startup, you might work directly with the Head of Engineering and one or two developers to do all of this. If you work for a company that’s about to go public in 2022, you might set up entirely new AI-focused product teams complete with an ML-first Product Manager, a Data Scientist, Machine Learning Engineers, and an MLOps Engineer.
What your organization does tomorrow is going to depend more on what your organization already does today.
Sound similar to the “the problem is still the problem?”
Yup, that’s because it is.
Back to the Top
With all of that said, here I provide an unautomatable map of MLOps problem and solution space to help you with your AI strategy in 2022.


And finally, we’ll end where we began, with those top-level assertions; the three bullets that I want you to leave knowing and remembering, that will hopefully help you extract some signal from all of this MLOps noise.
MLOps business value is business-model dependent
It is hard to create value; start close to your bottom line
Running lean and setting up automatic data capture is underrated
Good luck practitioners!








